RDB 개념 정리
DatabaseRDB데이터 모델링리팩토링
오늘은 개인 프로젝트인 메이플 헬퍼를 개발하는데
지금은 유저 데이터를 구조화해서 로컬스토리지에 저장해두고 사용하는 방식이다. 기능을 계속 붙이다 보니, API 요청 로직과 데이터 가공 로직이 한 함수에 섞여 있는 부분이 늘었다. 이 구조는 유지보수도 어렵고, 데이터 구조를 바꾸기 어려운 문제가 있다.
- API 요청 로직과 데이터 가공 로직 분리
- 기능 확장을 고려해서 데이터 구조를 다시 설계
이 과정에서 “데이터를 어떻게 나눠서 저장하고, 어떤 기준으로 연결할지”를 더 명확하게 잡고 싶었다. 그래서 RDB 개념부터 짧게 정리하고 넘어간다.
RDB란?
RDB는 관계형 데이터베이스(Relational Database) 모델을 기반으로, 데이터를 테이블 형태로 저장하고 테이블 간 관계로 데이터를 관리하는 방식이다.
실제로 개발에서 만나는 건 보통 “RDBMS(관계형 데이터베이스 관리 시스템)”다.
- RDB: 데이터 모델(개념)
- RDBMS: 그 모델을 구현한 소프트웨어(MySQL, PostgreSQL 같은 것)
미리 알아두면 좋은 키워드
- 테이블(Table): 엑셀 시트 한 장 같은 단위
- 행(Row): 한 개의 데이터(한 유저, 한 캐릭터, 한 기록)
- 열(Column): 속성(이름, 이메일, 레벨 등)
- 기본 키(Primary Key, PK): 행을 유일하게 구분하는 값(id)
- 외래 키(Foreign Key, FK): 다른 테이블의 PK를 참조하는 값
- 관계(Relationship): 1:1, 1:N, N:M 같은 연결 구조
주요 특징
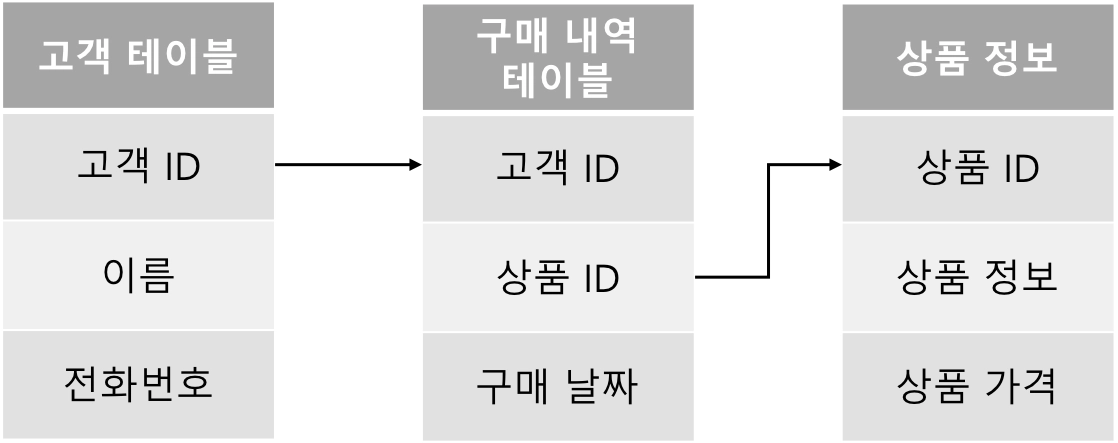
테이블 구조
데이터를 행/열 구조로 저장한다. 구조가 고정되어 있어서 “데이터 형태가 어떤지”가 명확해진다.
관계(Join)
PK/FK로 테이블 간 데이터를 연결할 수 있다. 중복을 줄이고, 필요할 때만 합쳐서 조회하는 형태로 설계할 수 있다.
SQL 사용
저장/조회/수정/삭제를 SQL로 다룬다. “필요한 데이터만 정확히 가져오기”가 가능해진다.
데이터 무결성
키 제약조건 같은 규칙으로 데이터의 일관성을 강제할 수 있다. 예를 들어 “없는 유저 id로 기록이 저장되는 상황”을 구조적으로 막을 수 있다.